Update: King, the maker of Candy Crush, has request Candy Crush Cracker be removed from the Chrome Extension store. Due to this, it can no longer be installed directly via the Chrome Extension store, and must be downloaded and installed from its source instead. Links below have been updated to point at the new location, which contains the source and installation instructions.
After receiving a lot of interest in Trivia Cracker, a Chrome extension that lets you easily cheat in the popular game Trivia Crack, I decided it might be interesting to see if the same kinds of vulnerabilities existed in other popular games. Given its insane popularity, the first game I thought to investigate, of course, was Candy Crush.
For those of you living under a rock, Candy Crush Saga is a match-three puzzle game for Facebook, iPhone, and Android, released back in 2012. Even though it is essentially a re-skinned Bejeweled, Candy Crush has managed to ride the “most popular” app store charts unlike any game before it. Even now, three years after its release, it’s still going strong as a top app in both the iOS and Google Play app stores. And that’s not to mention the insane 75 million likes Candy Crush has racked up on Facebook.
Given its popularity, you’d think the developers of such a polished and successful game might have taken the time to implement it in a way that is secure from cheating. But, as it turns out, writing some code to cheat at Candy Crush is actually fairly simple. Just like with Trivia Crack, over the course of a weekend I was able to write and release a Chrome extension, Candy Crush Cracker, that converted me from a medicore-at-best Candy Crush player to a god-like crusher of candy. You can see Candy Crush Cracker in action below, where I use it to get extra lives and to beat levels with any score I want:
So what’s wrong with Candy Crush Saga’s implementation that allowed me to so easily build a tool that lets anyone cheat? In short – beating a level in Candy Crush is as easy as sending a request to the Candy Crush server, saying you beat the level. You can even send along a score – any score – to say you beat the level with that score. The details of the vulnerability, how I found it, and how I built a Chrome extension to take advantage of it are below.
1 – Finding the vulnerability
Many of my friends are Candy Crush fanatics, achieving scores and reaching levels I never would be able to naturally. But while my Candy-Crush-playing abilities have continually failed me, I figured maybe my reverse-engineering skills could take me to new candy-crushing heights. I suspected it might be possible to send my own requests to Candy Crush’s servers, or use some data in the responses sent to the client from Candy Crush’s servers, to gain an edge in the game. So, I started researching what kinds of data the Candy Crush client and server pass back and forth.
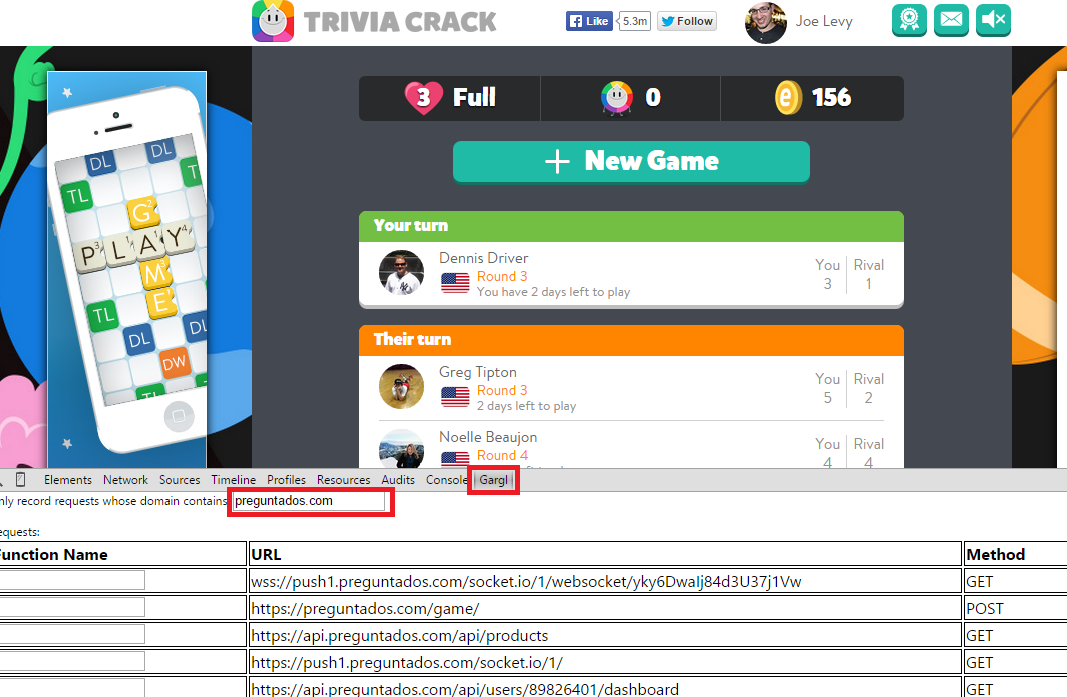
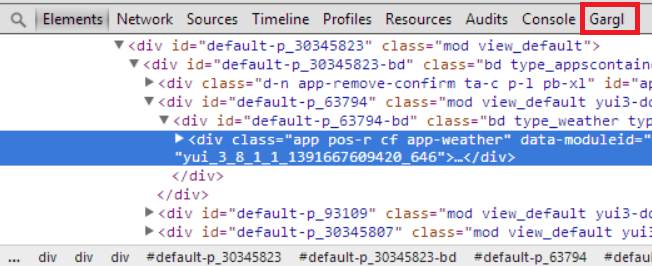
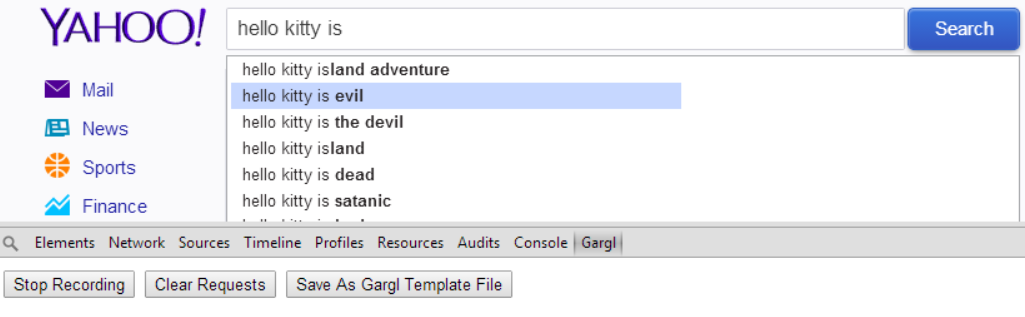
To inspect this data, I followed much the same process as with Trivia Crack. I played Candy Crush in my browser on Facebook, while recording and inspecting the requests and responses sent between Candy Crush’s client and server, using a tool I’d created previously called Gargl. Yes, I know I could have used Fiddler or Charles or Chrome’s Developer Tools to do the same. I decided to use Gargl instead because in addition to letting you view client/server requests/responses, Gargl also lets you modify and parameterize these requests, and then auto-generates modules in a programming language of your choice so you can make these same requests without writing a line of code. But more on that later.
Anyway, after telling Gargl to start recording and going to Candy Crush on Facebook in my browser, the first step was to figure out which of the many requests being sent on this Facebook page were related to Candy Crush, versus Facebook itself. Inspecting the HTML on the page showed that the Candy Crush flash content is embedded into Facebook via an iframe. The element right above this iframe was a form meant to post to a peculiar URL – https://candycrush.king.com/FacebookServlet/.

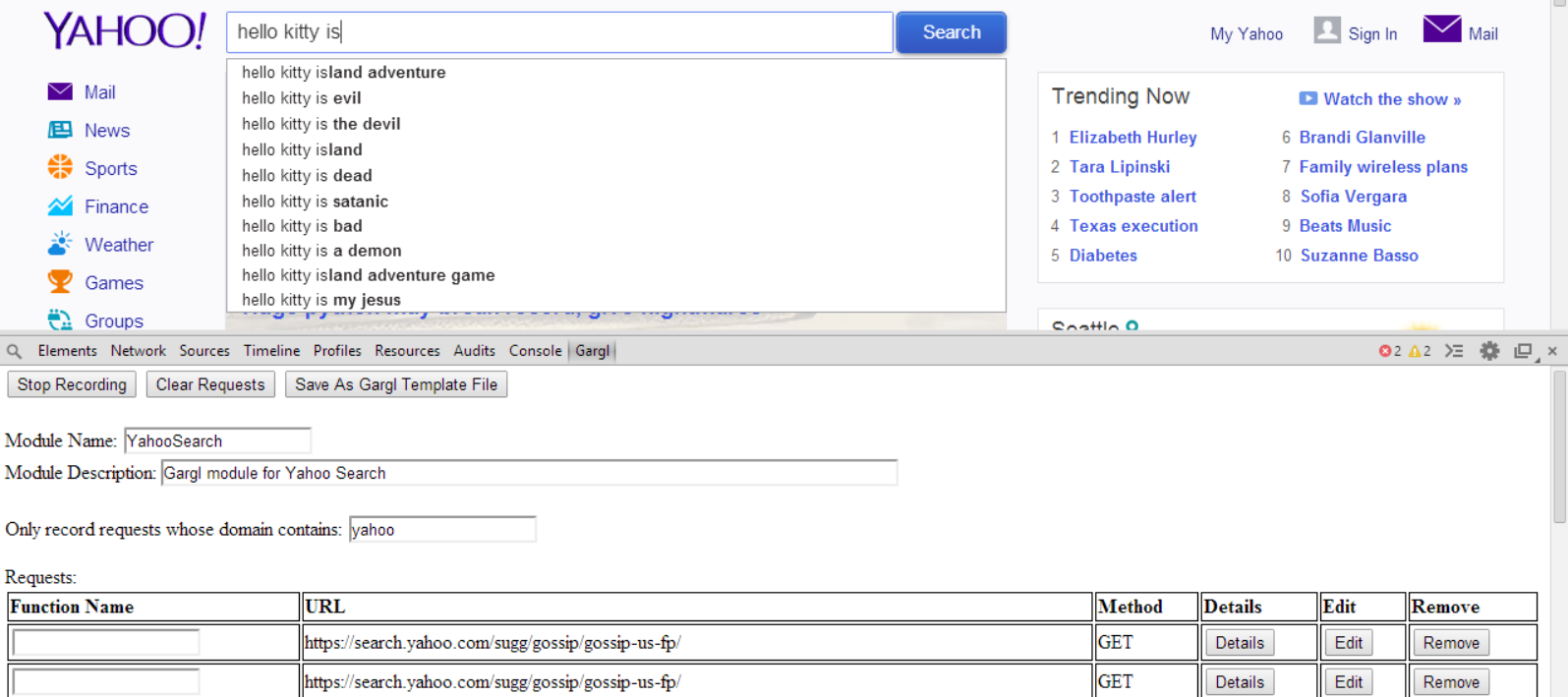
I knew King is the company that creates Candy Crush Saga, so I suspected this is the domain where Candy Crush is hosted. The next step was just to start playing Candy Crush, and as I played to look at the requests Gargl finds that the page is making to any URL containing “king.com”:
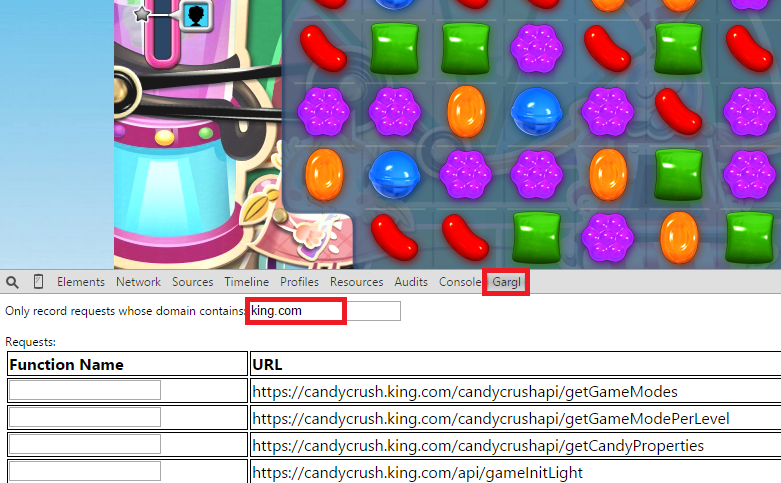
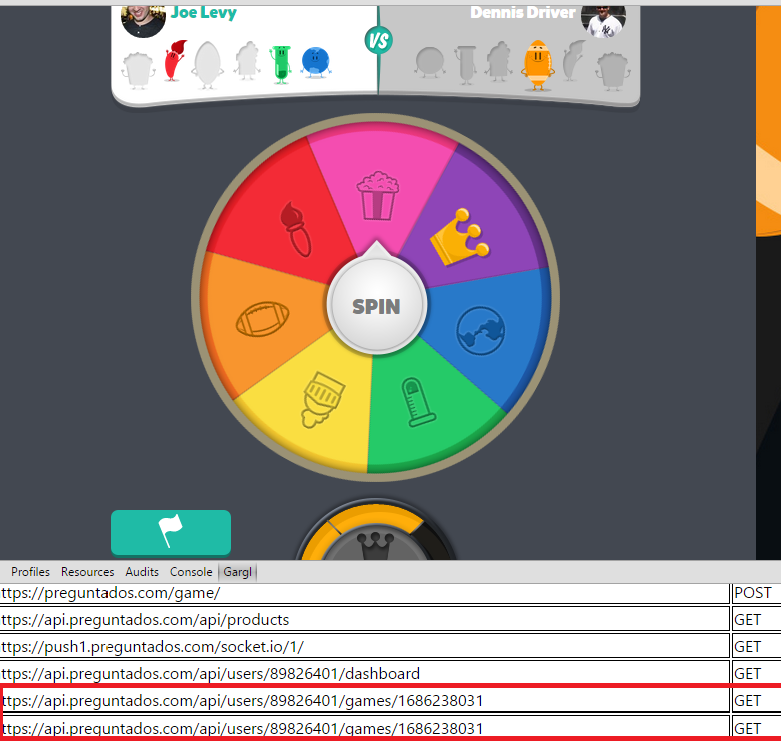
As I beat levels in Candy Crush, I noticed a new request seemed to be issued for each level. The requests seemed to be issued right after I successfully completed a level:
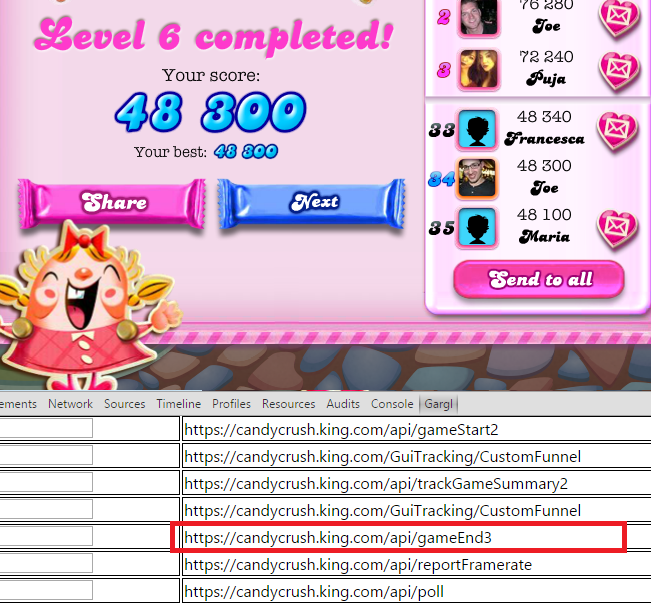
So, it seemed, maybe the client tells the Candy Crush server when a game is over. This made me think maybe the client doesn’t just say the game is over, but also says whether the user beat the level or not, and if the level was beaten, with what score the user beat the level. I figured I had a lead, and dug into the details of this “gameEnd” request.
2 – The vulnerability in detail
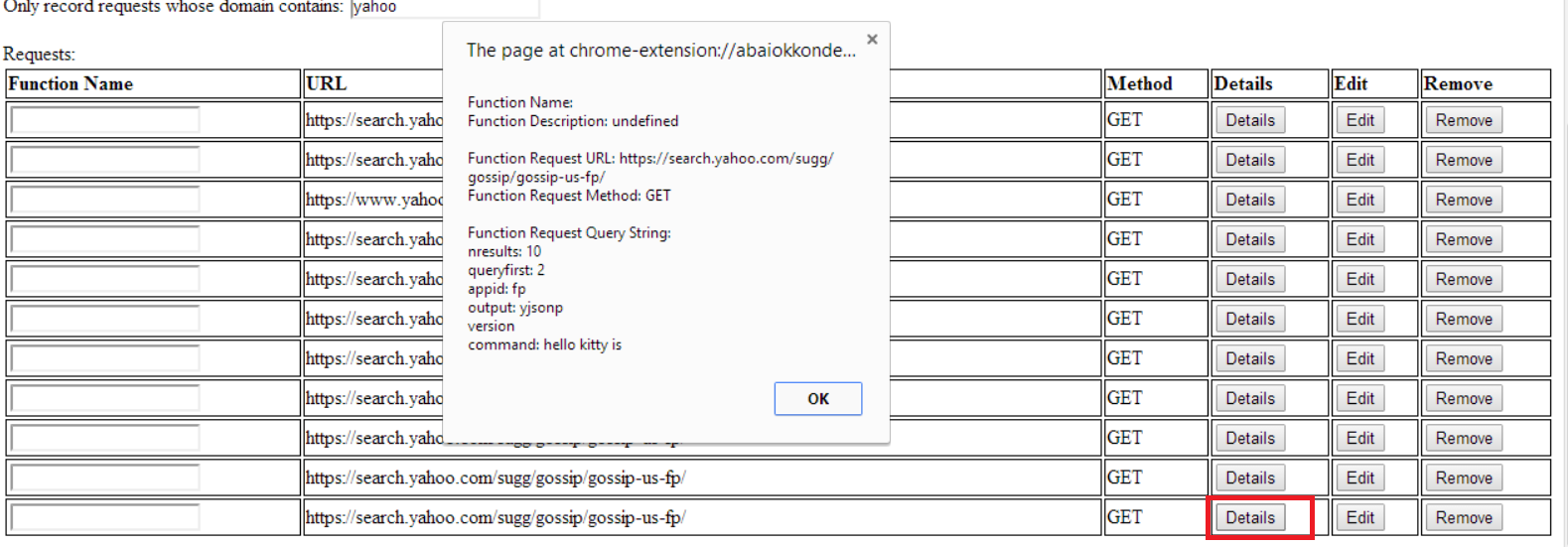
Using Gargl to look at the “candycrush.king.com/api/gameEnd3″ request/response in detail, I was able to confirm that it does indeed tell the server when the game is over, and the score with which the user beat the level:
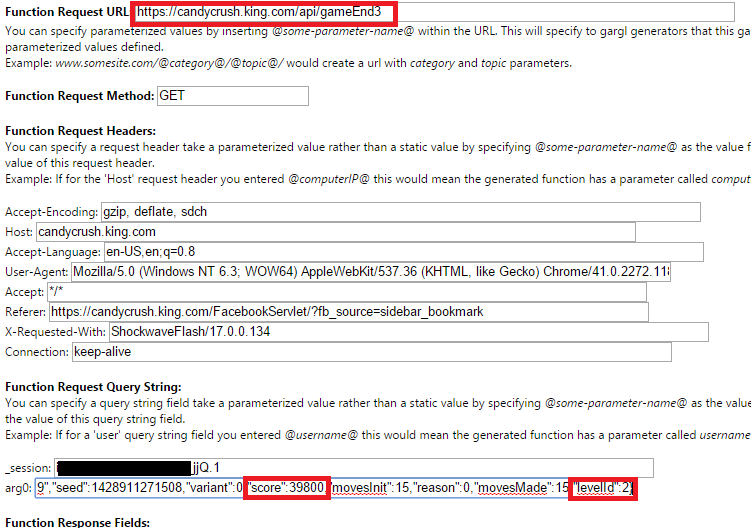
As you can see above, the request sent to the server contains, as a query string parameter, a JSON object containing the score the level was beaten with, the id of the level that was beaten, as well as a bunch of other information. The query string parameter’s name is a not-very-descriptive “arg0″ — maybe an attempt by the game’s creators to try to hide the fact that this parameter is the secret to making all your Candy Crush dreams come true!
The full value of the “arg0″parameter value looks like the below:
{
"episodeId": 1,
"timeLeftPercent": -1,
"movesLeft": 0,
"cs": "555b89",
"seed": 1428911271508,
"variant": 0,
"score": 39800,
"movesInit": 15,
"reason": 0,
"movesMade": 15,
"levelId": 2
}
From some experimentation and watching this request as I finished multiple levels, I was able to discern what most of the fields in arg0 mean, and where they come from. EpisodeId and levelId are used to identify the level, and can be found in the request sent to the server when you start playing a level — https://candycrush.king.com/api/gameStart2. Seed can also be found in this “gameStart” request, and seems to represent a random seed for how the layout of the candy in the level should look. In addition, every API request made to Candy Crush must be sent with an “_session” query string parameter, to identify the current user session. This value can also be found in the gameStart request, and really in any request to Candy Crush for that matter.
Here’s what the https://candycrush.king.com/api/gameStart2 request looks like:
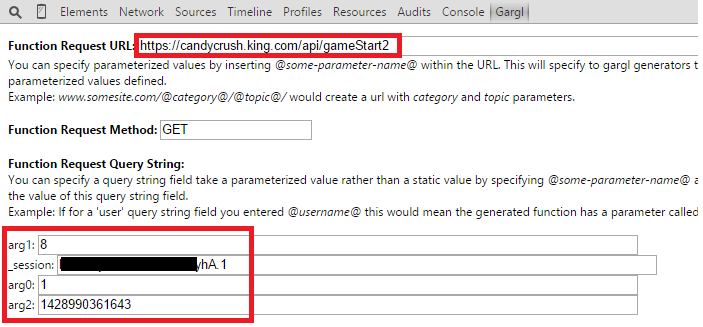
Again, it looks like Candy Crush’s creators are either really bad at coming up with creative parameter names, or they’re trying to obfuscate this information to make it harder to manipulate their API. EpisodeId is sent via a query string parameter called “arg0,” levelId is sent as “arg1,” and seed is sent as “arg2″. For some reason, they did decide to use a fairly descriptive name for the session token though — “_session.”
Other than episodeId, levelId, score, and seed, the rest of the fields in the gameEnd request’s arg0 query string parameter are unimportant, and can be hard-coded like above. That is, except for cs. Cs in this case probably stands for checksum, because if you do not send the right value for it, the request will fail. It turns out constructing the value of the checksum field is not all that difficult either. To get the correct checksum, simply MD5 hash a specific string and use the first 6 characters of that string as the checksum. The string to hash matches the format:
<episodeId>:<levelId>:<score>:-1:<userId>:<seed>:BuFu6gBFv79BH9hk
UserId is the only piece of information we don’t already have that is needed to construct the above string. It is sent in the “gameInit” request that happens every time you load Candy Crush Saga – https://candycrush.king.com/api/gameInitLight. You can make this request at any time (passing _session as a query string parameter, of course) and the response will contain your userId:
{
"currentUser": {
"userId": 1754400119,
"lives": 5,
"timeToNextRegeneration": -1,
"gold": 0,
"unlockedBoosters": [
],
"soundFx": false,
"soundMusic": false,
"maxLives": 5,
"immortal": false,
"mobileConnected": false,
"currency": "USD",
"altCurrency": "USD",
"preAuth": false
},
...
}
Great, we now have everything we need to make the gameEnd request! Let’s try popping this information into Fiddler’s composer, targeting the first level of the game, and see what happens when we enter a score of 100,000, calculate the checksum, make the gameEnd request, and then reload Candy Crush Saga:
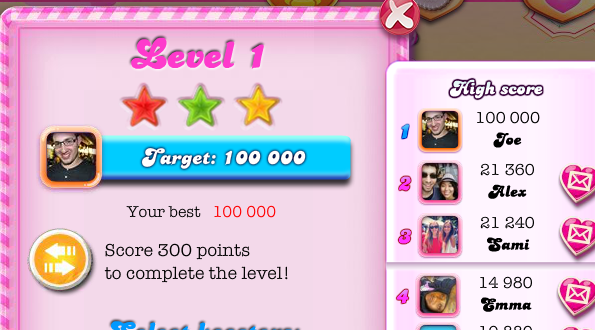
Well, my friends, it appears we’ve successfully cracked Candy Crush!
While Candy Crush Saga did take some defensive measures, allowing a single request to complete the level, with any score, is in direct conflict with the “Defensive Programming” practice of programming – particularly the “never trust the client” web programming principle. Since the server has no control over how the client acts, it can’t assume the client will not act in a malicious way, and so must protect itself. A better way of implementing “completing levels” would be to make the client send every move the user makes in the level to the server, and having the server determine if those moves successfully earn a score high enough to complete the level. While this method also isn’t perfect, it at least means the client, whether through manual user action or via some automated method, has to play the level instead of just telling the server “I win.”
However, Candy Crush did not do this, and instead trusts the client. Now it was just a matter of creating a malicious client to take advantage of the fact that the client can just tell the server it won any arbitrary level. Ideally, one that would be easy for non-technical users to install and use. Hmm…how about a Chrome extension that just adds a button to the Candy Crush game, when played on Facebook, that when clicked beats the current level automatically??
3 – Taking advantage of the vulnerability
As I mentioned above, Gargl allows you to take the requests you had it record, modify and parameterize them as needed, and then auto-generate modules in a programming language of your choice to make these same requests. I’m not going to go into the details of that process since you can look at one of my Gargl blog posts to find that info, but essentially I generated a Gargl template file for Candy Crush‘s various API requests, using the Gargl Chrome extension, and then used a Gargl generator to turn that template file into a Candy Crush JavaScript library. Using Gargl for this allowed me to create a JavaScript library that talks to Candy Crush’s servers, without writing a line of code to do so, and also to have a template file around for the future in case I want to do the same thing later with another programming language.
Once I had this Candy Crush JavaScript library, it was a simple matter of building a Chrome extension in JavaScript that runs on the domain loaded in the Candy Crush Facebook game page’s iframe (candycrush.king.com), adds a button to the HTML for the game, and when that button is clicked asks the user for a score, does the above steps to find episodeId, levelId, seed, _session, and userId, and then issues the gameEnd request to beat the current level.
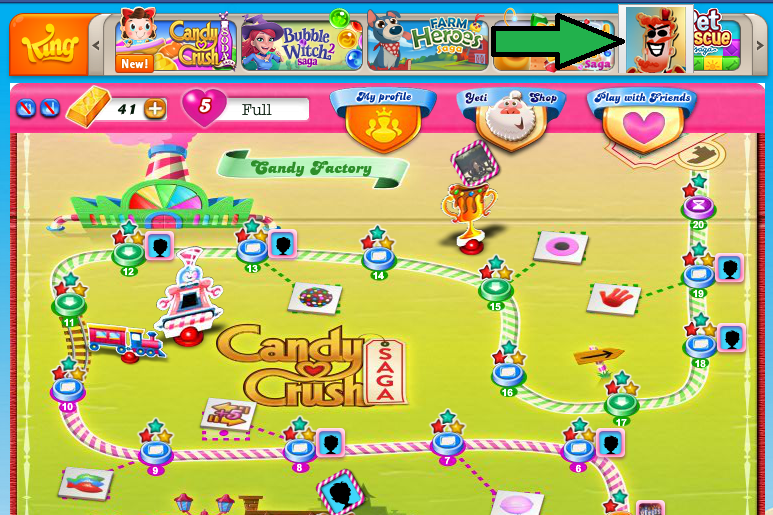
And just like that, Candy Crush Cracker was born! Curious about the exact details of how Candy Crush Cracker works? Check out the source code on GitHub.
Interested in hearing about other side projects like this one? Subscribe to my blog and follow me on Twitter. I’ll let you know when I think of something fun.












 Warning:
Warning: